



Kafka Consumer Groups: Bí quyết scaling hệ thống xử lý tin nhắn
Bạn đang xây dựng một hệ thống microservices cần xử lý hàng triệu tin nhắn mỗi giây? Chỉ dùng một Kafka consumer đơn độc sẽ nhanh chóng trở thành nút thắt cổ chai. Giải pháp nằm ở Kafka Consumer Groups – trái tim của khả năng scale ngang trong event-driven architecture.
Nếu bạn chưa rõ sự khác biệt giữa Kafka và các message broker khác, hãy xem lại bài so sánh Kafka vs RabbitMQ trước khi đi sâu vào chi tiết kỹ thuật dưới đây.
Consumer Group là gì? (Định nghĩa cốt lõi)
Kafka Consumer Group là một tập hợp các consumer instance có chung group.id, cùng làm việc để đọc message từ một hoặc nhiều partition của một Kafka topic. Nguyên tắc quan trọng nhất: mỗi partition chỉ được gán cho tối đa một consumer trong cùng một group. Điều này đảm bảo:
- Load balancing – các partition được phân bố đều giữa các consumer.
- Ordering per partition – thứ tự message trong một partition được bảo toàn.
Nói một cách dễ hiểu: Consumer group giống như một “đội ngũ” mà Kafka dùng để chia việc xử lý dữ liệu một cách song song.
Tại sao một Consumer là không đủ?
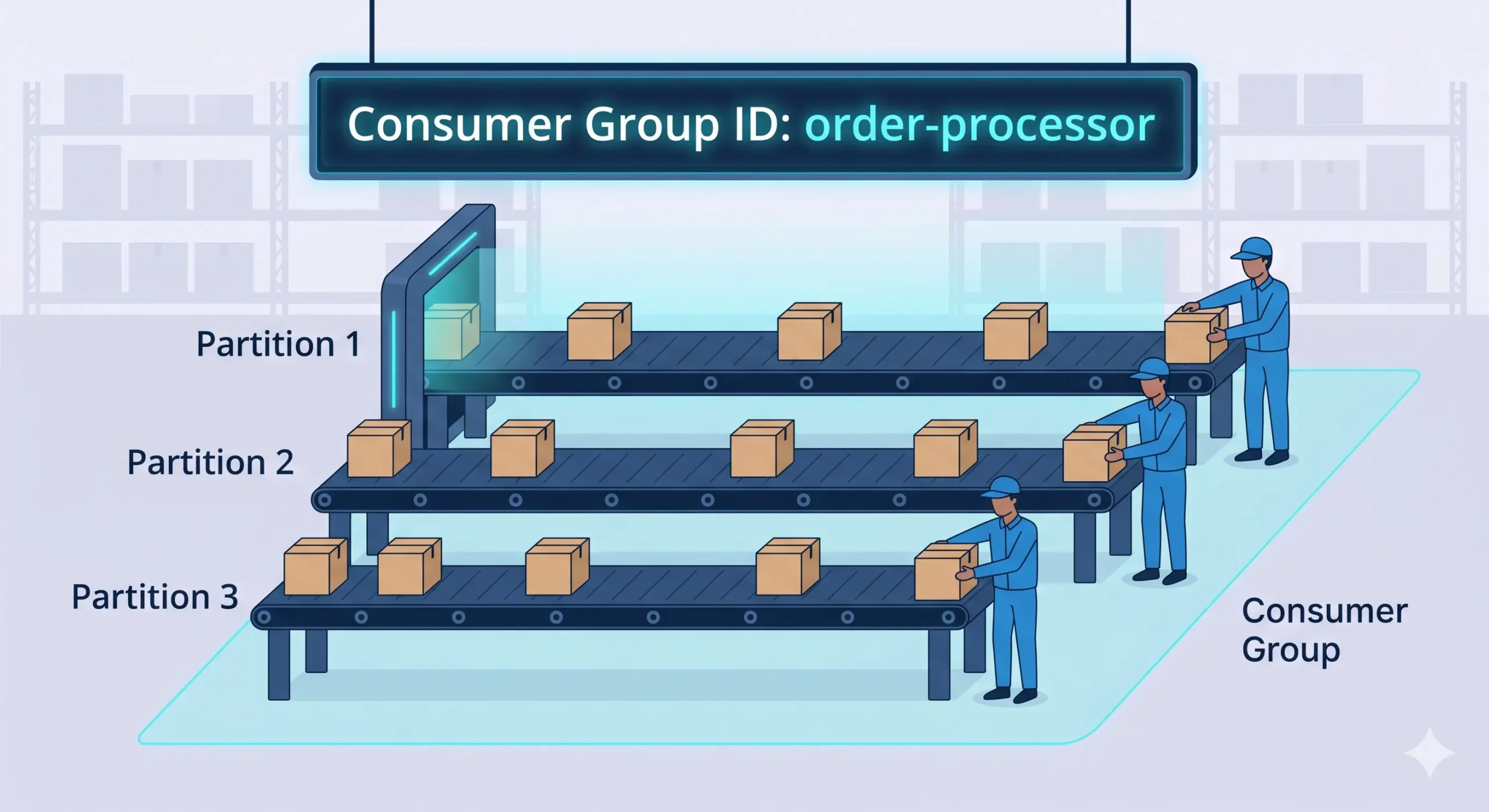
Một Kafka consumer đơn (single consumer) có thể đọc từ một hoặc nhiều partition. Khi lượng tin nhắn tăng vọt, consumer đơn độc bị quá tải → consumer lag (tin nhắn tồn đọng) tăng cao. Đây là vấn đề thường gặp trong thực tế với các kỹ sư backend.
Hình ảnh trực quan: Hãy tưởng tượng một bưu cục có 10 băng chuyền (partitions) và chỉ một nhân viên bốc xếp. Nhân viên đó không thể chạy nhanh bằng tốc độ băng chuyền. Giải pháp: Tuyển thêm nhân viên – mỗi người phụ trách một hoặc vài băng chuyền riêng.
Consumer Group ID: Sợi dây liên kết các instance
Mỗi consumer group được xác định bởi tham số group.id. Tất cả consumer có cùng group.id sẽ tự động phối hợp với nhau. Consumer group cho phép bạn scale theo chiều ngang một cách trong suốt: khi thêm consumer instance mới, Kafka tự động điều chỉnh việc phân chia partition.
Code minh họa: Khai báo Consumer Group với KafkaJS (Node.js)
Ví dụ dưới đây khởi tạo một consumer thuộc group "order-processor" bằng thư viện KafkaJS (Kafka 3.x).
const { Kafka } = require('kafkajs')
const kafka = new Kafka({
clientId: 'order-app',
brokers: ['broker1:9092', 'broker2:9092']
})
const consumer = kafka.consumer({
groupId: 'order-processor' // ← Consumer Group ID
})
const run = async () => {
await consumer.connect()
await consumer.subscribe({ topic: 'orders', fromBeginning: false })
await consumer.run({
eachMessage: async ({ topic, partition, message }) => {
console.log(`[group: order-processor][partition ${partition}] received: ${message.value}`)
// Xử lý nghiệp vụ ở đây
}
})
}
run().catch(console.error)Giải thích code:
groupId: 'order-processor'– định danh nhóm. Các instance chạy cùnggroupIdsẽ chia sẻ tải.subscribe({ topic: 'orders' })– consumer đăng ký nhận tin từ topicorders.eachMessage– callback xử lý từng message. Không nên đặt logic nặng đồng bộ ở đây (xem best practices).
⚠️ Lưu ý: Consumer group ID nên mang ý nghĩa logic nghiệp vụ (ví dụ: order-processor, payment-notifier). Không thay đổi trừ khi bạn muốn start lại từ đầu hoặc xử lý lại dữ liệu.
Mối quan hệ giữa Partition và Consumer
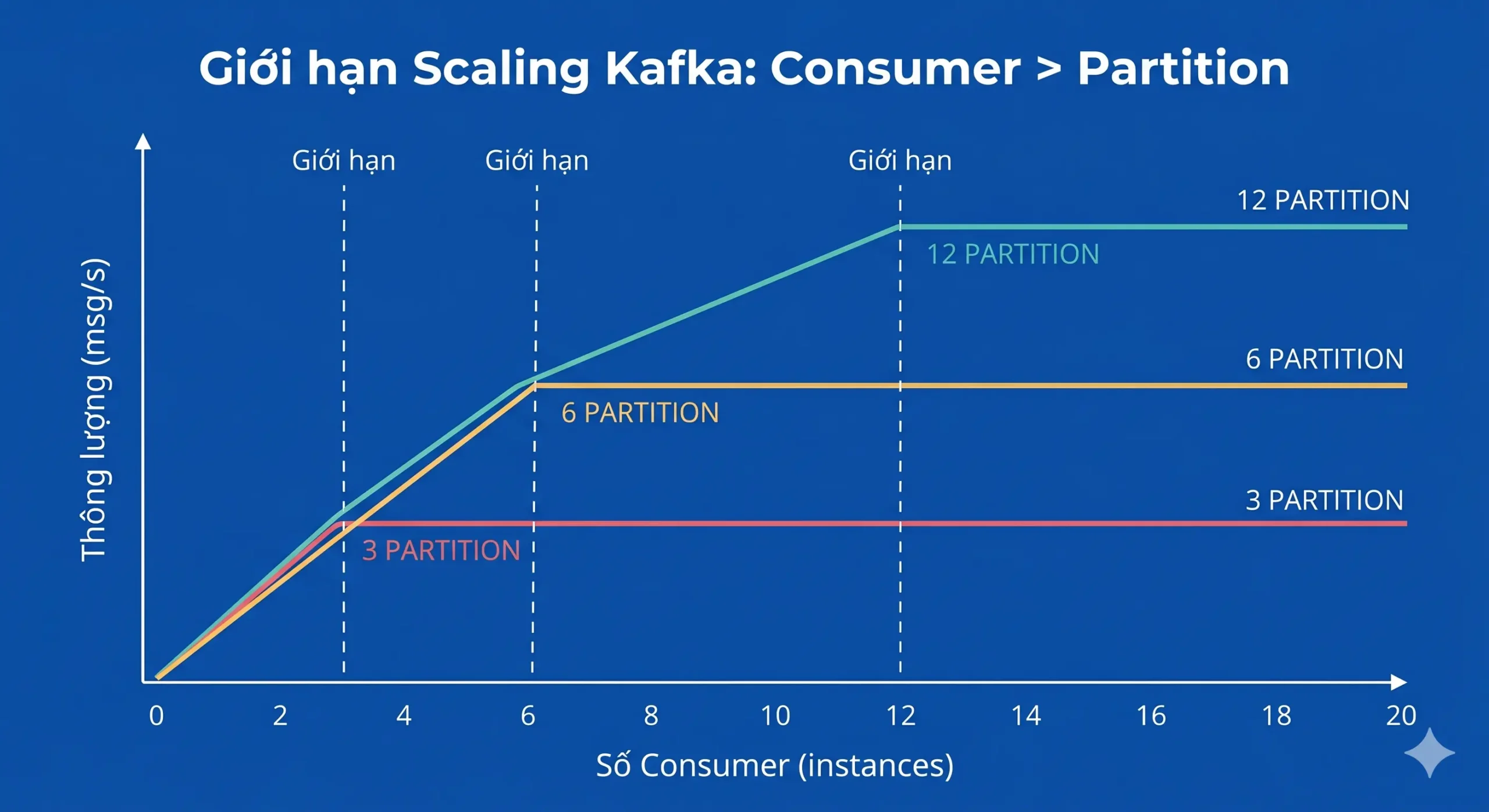
Quy tắc nền tảng: Số lượng consumer active trong một group không được vượt quá tổng số partition của topic đang subscribe.
- Nếu số partition = 6, bạn có thể scale tối đa 6 consumer chạy song song.
- Nếu số partition = 6 nhưng bạn khởi chạy 8 consumer: 2 consumer sẽ idle (không nhận partition, chỉ ngồi chơi).
Giới hạn scaling – Sai lầm kinh điển
Nhiều đội nhóm nhầm tưởng cứ thêm consumer là tăng throughput. Nhưng khi số consumer > số partition, hiệu suất không tăng – bạn chỉ lãng phí tài nguyên.
| Số partition | Số consumer | Consumer hoạt động | Consumer rảnh |
|---|---|---|---|
| 3 | 1 | 1 | 0 |
| 3 | 3 | 3 | 0 |
| 3 | 5 | 3 | 2 (lãng phí) |
Làm thế nào để scale cao hơn?
- Tăng số partition của topic – nhưng hãy làm trước khi đưa vào production, vì thay đổi sau khi có dữ liệu sẽ ảnh hưởng đến phân phối (xem cảnh báo bên dưới).
- Thiết kế nhiều consumer group khác nhau cho các luồng xử lý độc lập.
⚠️ Cảnh báo quan trọng: Nếu topic đã có dữ liệu và bạn tăng số partition, các message có cùng key có thể rơi vào partition khác – điều này phá vỡ thứ tự theo key (key-based ordering). Hãy cân nhắc kỹ trước khi thay đổi partition count.
Hiện tượng Rebalance: Khi nào nó xảy ra?
Rebalance là quá trình Kafka phân phối lại các partition giữa các consumer trong cùng một group. Đây là cơ chế tự động giúp thích ứng với sự thay đổi thành viên trong nhóm.
Các sự kiện kích hoạt rebalance:
- Consumer mới tham gia group (scale up).
- Consumer rời nhóm (tắt máy, crash, hoặc mất kết nối).
- Consumer gửi heartbeat không kịp (do xử lý quá lâu trong vòng
poll). - Thay đổi số partition của topic đang subscribe.
Cơ chế Rebalance Protocol mới trong Kafka 3.x
✅ Đã kiểm chứng từ Apache Kafka Documentation (version 3.2+):
Kafka 3.x giới thiệu Incremental Cooperative Rebalancing thay thế cho “Eager Rebalancing” cũ. Không như phiên bản cũ (tạm dừng toàn bộ nhóm), Incremental Cooperative Rebalancing chỉ thu hồi một phần partition cần thiết, giữ nguyên các partition không bị ảnh hưởng. Quá trình này gồm 3 bước:
- Join & Sync: Consumer đăng ký, leader group đề xuất assignment.
- Revocation: Chỉ thu hồi các partition cần chuyển.
- Assignment mới: Các partition được gán lại dần dần.
Tác động phụ: Trong suốt quá trình rebalance, toàn bộ consumer trong group tạm dừng xử lý tin nhắn. Nếu rebalance xảy ra quá thường xuyên, hệ thống bị gián đoạn liên tục, throughput giảm sâu.
Chiến lược gán partition (Partition Assignors)
Kafka hỗ trợ nhiều chiến lược gán partition, ảnh hưởng trực tiếp đến rebalance:
- Range (mặc định trong Kafka cũ): gán theo khoảng partition.
- RoundRobin: luân phiên đều.
- Sticky và Cooperative Sticky (mặc định từ Kafka 3.x + Raft) – giảm thiểu di chuyển partition giữa các lần rebalance.
Bạn có thể cấu hình qua tham số partition.assignment.strategy.
Lỗi thường gặp và cách khắc phục
❌ Lỗi 1: Consumer nhiều hơn Partition
Hậu quả: Consumer rảnh rỗi (idle), tài nguyên bỏ phí.
Sửa: Luôn đảm bảo số consumer ≤ số partition. Nếu cần song song cao, hãy tăng partition từ thiết kế ban đầu.
❌ Lỗi 2: Xử lý message quá lâu trong vòng lặp poll
Hậu quả: Heartbeat timeout → bị coi là “chết” → kích hoạt rebalance.
Sửa:
- Sử dụng
max.poll.interval.ms(trong Kafka Java) hoặcmaxPollInterval(trong KafkaJS) – mặc định 5 phút – để tăng thời gian cho phép xử lý. - Hoặc commit offset bất đồng bộ, đưa message vào queue riêng để xử lý ở background.
❌ Lỗi 3: Quên commit offset
Hậu quả: Khi restart consumer, nó đọc lại toàn bộ message chưa được commit, dẫn đến xử lý trùng lặp (duplicate processing).
Sửa: Dùng auto-commit cẩn thận, hoặc commit thủ công sau khi xử lý thành công.
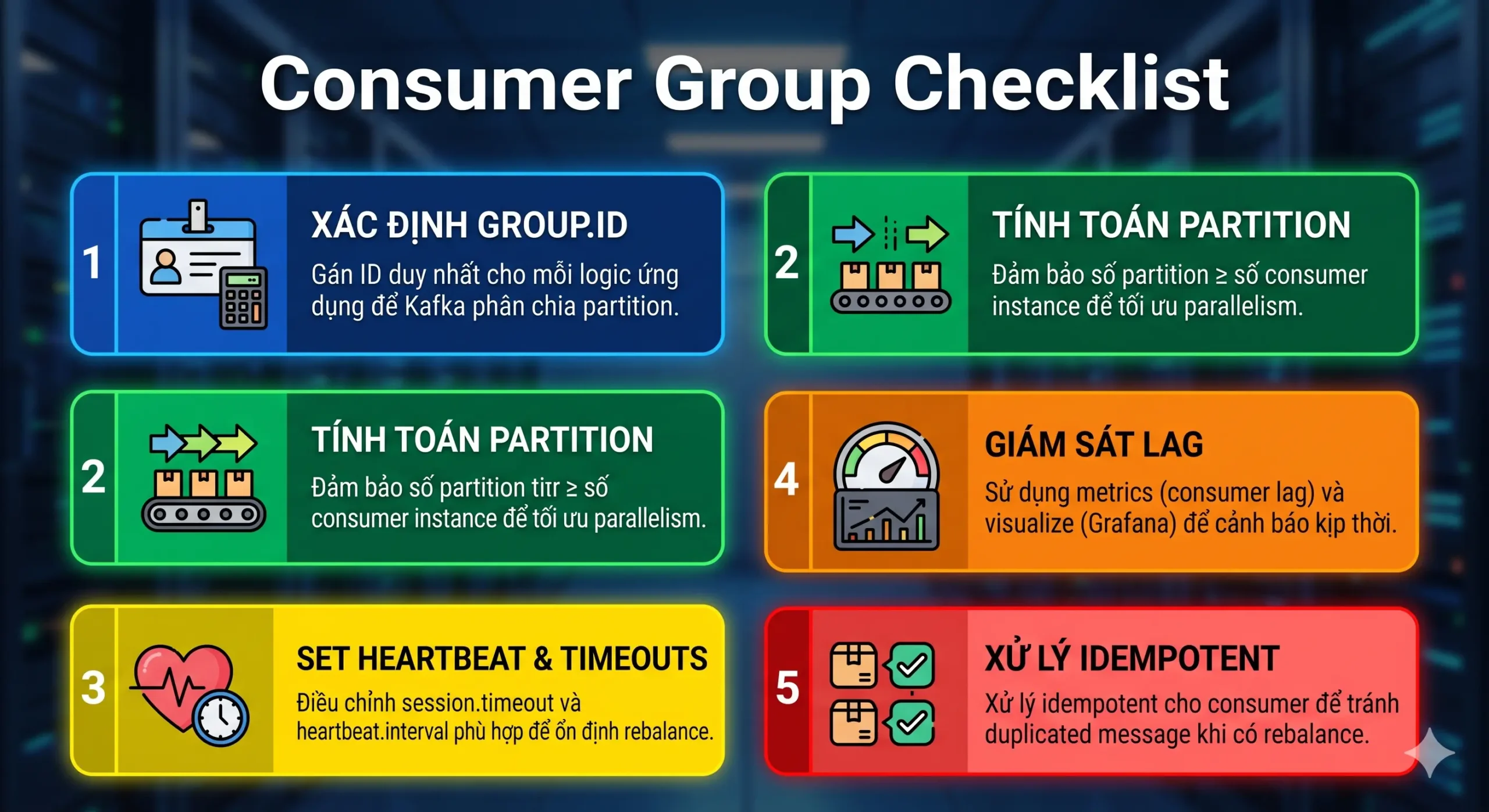
Best practices cho Consumer Group trong production
-
Monitor Consumer Lag thường xuyên
- Sử dụng lệnh CLI:
kafka-consumer-groups --bootstrap-server localhost:9092 --group order-processor --describe - Hoặc dùng các công cụ như Burrow, Prometheus + Kafka Exporter.
- Lag là số message chưa được xử lý. Lag tăng bất thường báo hiệu quá tải hoặc rebalance kéo dài.
- Sử dụng lệnh CLI:
-
Tránh xử lý tác vụ nặng trong vòng lặp
poll
Đọc message nhanh, đưa vào internal queue, xử lý background. Giữpollshort để heartbeat luôn được gửi kịp thời. -
Cấu hình thời gian rebalance hợp lý
session.timeout.ms: mặc định 45s – thời gian tối đa cho phép mất heartbeat.heartbeat.interval.ms: nên đặt bằng 1/3session.timeout.ms.max.poll.interval.ms(Java) /maxPollInterval(KafkaJS): tăng nếu xử lý mất nhiều hơn vài phút.
-
Thiết kế idempotent (tính đơn đạo) khi không có exactly‑once
Ngay cả với commit offset, crash vẫn có thể gây xử lý lại message. Hãy đảm bảo việc xử lý lại (replay) không gây hậu quả xấu. -
Phân bố dữ liệu đều giữa các partition
Tránh hot partition – nếu có sự chênh lệch lớn, hãy cân nhắc thiết kế key (ví dụ: thêm salt) để dữ liệu phân bố đồng đều hơn.
Câu hỏi thường gặp
1. Làm sao để tránh rebalance quá thường xuyên?
- Tăng
session.timeout.msvàheartbeat.interval.msđể chịu được các đoạn mạng không ổn định ngắn. - Đảm bảo thời gian xử lý mỗi message không vượt quá
max.poll.interval.ms(hoặcmaxPollInterval). - Tránh thêm/bớt consumer liên tục trong thời gian ngắn (có thể dùng thuật toán backoff khi scale tự động).
- Nâng cấp lên Kafka 2.4+ để sử dụng Incremental Cooperative Rebalancing, giảm số lần “stop-the-world”.
2. Có thể một consumer thuộc nhiều group không?
Có. Một consumer instance (client) có thể chạy nhiều luồng, mỗi luồng tham gia một consumer group khác nhau. Trong Kafka, các consumer group là độc lập. Ví dụ: cùng một ứng dụng vừa là consumer group group-A cho topic orders, vừa là consumer group group-B cho topic payments. Tuy nhiên, mỗi consumer object chỉ thuộc một group. Để thuộc nhiều group, bạn cần khởi tạo nhiều consumer riêng biệt.
Kết luận
Kafka Consumer Groups là công cụ mạnh mẽ để scale hệ thống xử lý tin nhắn theo chiều ngang. Bằng cách hiểu rõ mối quan hệ giữa partition và consumer, cơ chế rebalance (đặc biệt là Incremental Cooperative Rebalancing trong Kafka 3.x), và các lỗi thường gặp, bạn có thể thiết kế một hệ thống event-driven vừa thông suốt vừa hiệu quả.
Hành động ngay:
- Kiểm tra lại thiết kế topic partition hiện tại.
- Thiết lập giám sát consumer lag (dùng CLI hoặc Prometheus).
- Luôn code consumer với tư tưởng idempotent.
Xem lại bài so sánh Kafka vs RabbitMQ nếu bạn muốn có cái nhìn tổng quan trước khi đi sâu vào các chi tiết kỹ thuật như trên nhé!