




Kafka vs RabbitMQ: Cuộc chiến của các Message Broker
Trong thế giới Microservices, việc các dịch vụ giao tiếp với nhau qua tin nhắn (messaging) là điều bắt buộc. Tuy nhiên, đứng trước hai “gã khổng lồ” Apache Kafka và RabbitMQ, nhiều kỹ sư thường bị bối rối.
Để dễ hình dung, hãy tưởng tượng:
- RabbitMQ như một người đưa thư tận tụy: Anh ta nhận thư, phân loại cực nhanh và trao tận tay người nhận. Khi thư đã giao xong, anh ta sẽ tiêu hủy bản sao để dọn chỗ cho thư mới.
- Kafka như một thư viện khổng lồ: Mọi cuốn sách (dữ liệu) đều được đánh số thứ tự và lưu trữ trên kệ theo thời gian. Người đọc (Consumer) tự đến kệ, tìm đúng vị trí mình đã đọc dở để tiếp tục, và cuốn sách vẫn nằm đó cho những người khác đến đọc sau.
Bài viết này sẽ giúp bạn phân tích sâu hơn về hai triết lý này.
1. Kiến trúc khác biệt: Smart Broker vs Smart Consumer
Sự khác biệt cốt lõi nằm ở cách hệ thống quản lý tin nhắn và trạng thái của chúng.
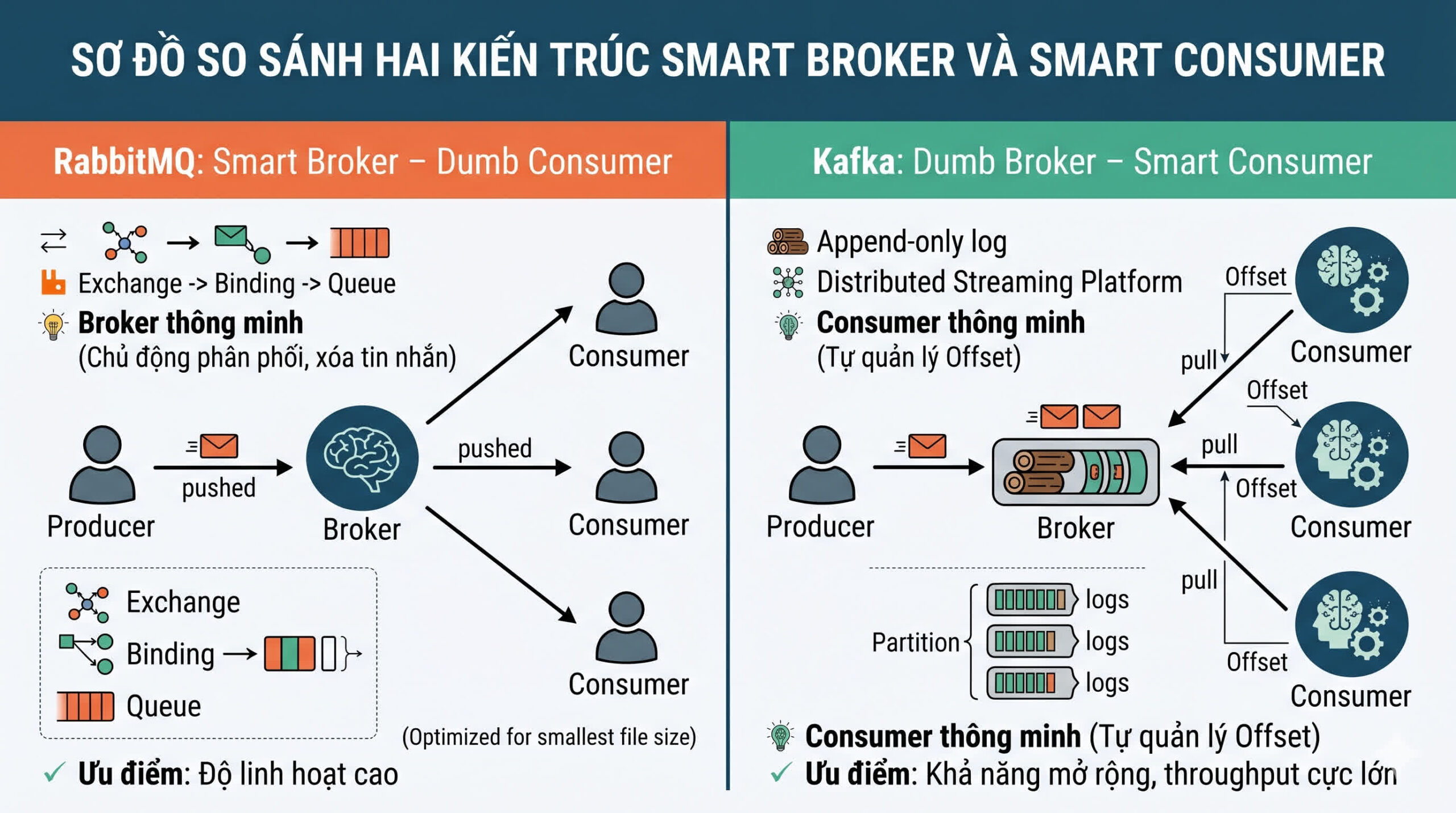
RabbitMQ: Smart Broker – Dumb Consumer
RabbitMQ sử dụng mô hình Message Queue. Broker (RabbitMQ) đóng vai trò trung tâm “thông minh”: nó theo dõi xem Consumer nào đang rảnh, phân phối tin nhắn, chờ xác nhận (ACK) và chủ động xóa tin nhắn khỏi hàng đợi khi đã hoàn thành.
- Cơ chế: Exchange -> Binding -> Queue.
- Ưu điểm: Độ linh hoạt trong điều phối cực cao.
Kafka: Dumb Broker – Smart Consumer
Ngược lại, Kafka là một Distributed Streaming Platform. Nó lưu trữ tin nhắn dưới dạng các bản ghi (logs) liên tục trong các Partition. Broker của Kafka rất “ngây ngô”, nó không quan tâm ai đã đọc gì. Thay vào đó, Consumer phải tự quản lý vị trí của mình thông qua một con trỏ gọi là Offset.
- Cơ chế: Append-only log.
- Ưu điểm: Khả năng mở rộng (scalability) và throughput cực lớn.
2. Bảng so sánh tổng hợp các tiêu chí cốt lõi
Để có cái nhìn nhanh nhất về việc chọn Message Queue tốt nhất cho dự án, hãy tham khảo bảng sau:
| Tiêu chí | RabbitMQ | Apache Kafka |
|---|---|---|
| Mô hình | Message Queue (Push) | Log-based (Pull) |
| Triết lý | Smart Broker – Dumb Consumer | Dumb Broker – Smart Consumer |
| Độ trễ (Latency) | Cực thấp (Micro-seconds) | Thấp (Milli-seconds) |
| Băng thông (Throughput) | Trung bình (~10k – 50k msg/s) | Rất cao (Hàng triệu msg/s) |
| Lưu trữ dữ liệu | Xóa ngay sau khi xác nhận (Ack) | Lưu trữ lâu dài (Replay được) |
| Định tuyến (Routing) | Rất linh hoạt (Exchange/Binding) | Đơn giản (Topic/Partition) |
3. Phân tích chuyên sâu
3.1. Độ trễ và Băng thông
- RabbitMQ: Được tối ưu cho độ trễ cực thấp. Nó xử lý tin nhắn ngay lập tức khi chúng đến. Tuy nhiên, khi số lượng tin nhắn lên đến hàng triệu/giây, RabbitMQ có thể gặp hiện tượng nghẽn cổ chai do gánh nặng quản lý trạng thái của từng message.
- Kafka: Nhờ cơ chế ghi tuần tự vào đĩa (Sequential I/O) và Zero-copy, Kafka xử lý hàng Terabyte dữ liệu mỗi ngày mà không hề hấn gì. Đổi lại, độ trễ thường cao hơn RabbitMQ một chút vì cơ chế gom batch tin nhắn để tối ưu throughput.
Dẫn chứng: Theo các benchmark thực tế, Kafka thường vượt trội hơn RabbitMQ về throughput gấp 10-50 lần trong các điều kiện xử lý stream dữ liệu lớn.
3.2. Khả năng lưu trữ (Data Retention)
- RabbitMQ: Tin nhắn bị xóa ngay sau khi Consumer xác nhận đã xử lý xong. Nó không được thiết kế để làm nơi lưu trữ dữ liệu.
- Kafka: Tin nhắn được lưu trữ dựa trên cấu hình thời gian (ví dụ: 7 ngày) hoặc kích thước file. Điều này cực kỳ hữu ích khi bạn cần “tua lại” (replay) dữ liệu để khắc phục sự cố hoặc train lại model AI.
4. Case Study: Khi nào chọn cái nào?
Dùng RabbitMQ cho hệ thống giao dịch/thông báo
Ví dụ (Shopee): Khi bạn nhấn “Đặt hàng”, hệ thống cần gửi thông báo cho kho, gửi email cho bạn và cập nhật trạng thái đơn hàng.
- Tại sao chọn RabbitMQ? Các tác vụ này cần routing phức tạp (đơn hàng nội địa vào queue A, quốc tế vào queue B), yêu cầu độ trễ thấp để khách hàng nhận được thông báo ngay lập tức.
Dùng Kafka cho phân tích Log/Real-time Data
Ví dụ (Netflix/Spotify): Theo dõi hành vi người dùng (click, pause, search) để gợi ý phim/nhạc trong thời gian thực.
- Tại sao chọn Kafka? Mỗi giây có hàng tỷ sự kiện. Kafka cho phép nhiều hệ thống khác nhau (Recommendation Engine, Billing, Data Warehouse) cùng đọc một luồng dữ liệu đó tại các thời điểm khác nhau mà không làm giảm hiệu năng hệ thống.
5. Demo Code: Producer đơn giản với RabbitMQ (Node.js)
Dưới đây là cách kết nối và gửi một tin nhắn cơ bản bằng thư viện amqplib.
const amqp = require('amqplib');
async function sendOrderNotification() {
let connection;
try {
// 1. Kết nối tới RabbitMQ Server
connection = await amqp.connect('amqp://localhost');
const channel = await connection.createChannel();
const queueName = 'order_notifications';
const msg = JSON.stringify({ orderId: 12345, status: 'SUCCESS', timestamp: Date.now() });
// 2. Đảm bảo queue tồn tại
await channel.assertQueue(queueName, { durable: true });
// 3. Gửi tin nhắn vào queue
channel.sendToQueue(queueName, Buffer.from(msg), { persistent: true });
console.log(" [x] Sent: %s", msg);
// Đóng kết nối an toàn sau khi hàng đợi đã flush dữ liệu
await channel.close();
} catch (error) {
console.error("Lỗi RabbitMQ:", error);
} finally {
if (connection) await connection.close();
}
}
sendOrderNotification();
Lưu ý kỹ thuật: Trong môi trường production, bạn không nên mở/đóng connection cho mỗi tin nhắn. Hãy giữ một connection ổn định và sử dụng cơ chế confirmSelect() để đảm bảo tin nhắn đã thực sự tới Broker.
6. Lỗi thường gặp và Best Practices
Lỗi thường gặp: Lạm dụng Kafka làm Message Queue truyền thống
Nhiều người cố gắng bắt chước tính năng định tuyến của RabbitMQ trong Kafka bằng cách tạo ra hàng nghìn Topic hoặc dùng Consumer logic để lọc dữ liệu.
- Hậu quả: Tăng overhead metadata và gây lãng phí tài nguyên Cluster.
- Cách xử lý: Nếu logic định tuyến thay đổi liên tục và phụ thuộc nhiều vào nội dung tin nhắn (Content-based routing), hãy dùng RabbitMQ.
Best Practices: Luôn có Dead Letter Queue (DLQ)
- Với RabbitMQ: Cấu hình
x-dead-letter-exchangeđể tự động đẩy các tin nhắn lỗi vào một queue riêng. - Với Kafka: Consumer nên bắt lỗi và đẩy tin nhắn lỗi vào một “Retry Topic” hoặc “DLQ Topic” riêng biệt để xử lý sau.
7. Xu hướng công nghệ 2026
- RabbitMQ Quorum Queues: Đã trở thành tiêu chuẩn cho các hệ thống yêu cầu tính sẵn sàng cao (High Availability), giúp RabbitMQ thu hẹp khoảng cách về khả năng chống mất dữ liệu so với Kafka.
- Kafka KRaft (KIP-500): Giờ đây Zookeeper đã hoàn toàn lùi vào quá khứ. Việc vận hành Kafka Cluster trở nên gọn nhẹ và dễ dàng hơn nhiều so với trước đây.
FAQ (Câu hỏi thường gặp)
1. Cái nào khó vận hành (Ops) hơn? Thông thường, Kafka khó hơn vì đòi hỏi hiểu biết về JVM, Disk I/O và Partitioning. RabbitMQ thân thiện hơn nhờ Management UI tích hợp sẵn rất trực quan.
2. Kafka có thể thay thế hoàn toàn RabbitMQ không? Không. RabbitMQ vẫn là “ông vua” trong các kịch bản cần Request-Reply, Complex Routing và xác nhận chi tiết mức tin nhắn (Message-level ACK).
Kết luận
Việc lựa chọn giữa Kafka và RabbitMQ không phải là tìm ra cái nào “mạnh hơn”, mà là tìm cái nào “hợp hơn”.
- Chọn RabbitMQ khi bạn cần sự linh hoạt, tin nhắn nhẹ, độ trễ thấp và định tuyến phức tạp.
- Chọn Kafka khi bạn đối mặt với Big Data, Event Streaming và cần khả năng lưu trữ để phân tích lịch sử.